Utiliser le big data pour connaître les habitudes de déplacement
L'exploitation des traces des mobinautes et l'open data ouvrent des perspectives intéressantes pour connaître les habitudes de déplacements des usagers. Couplées à des technologies d'intelligence artificielle, elles rendent possible la création de modèles prédictifs.
© Entropy
Pour définir ou adapter leur stratégie de mobilité, les collectivités recourent aujourd'hui essentiellement à des enquêtes ménages déplacements (EMD). Celles-ci permettent d'établir un diagnostic sur les pratiques existantes et de mettre en adéquation l'offre de transport avec les besoins des habitants. Réalisées en face à face, par téléphone ou par internet, les EMD sont particulièrement détaillées, offrent un ressenti intéressant mais ont pour inconvénients d'être onéreuses et ponctuelles en ne fournissant qu'une photographie instantanée, partielle, de la situation.
Intérêt et limites de données GPS
Des limites que les traces numériques laissées par les utilisateurs peuvent, au moins en théorie, lever. Première piste, l'exploitation des données de flux de mobilité. À Paris, Lille ou Rennes, les données de validation des titres de transport (anonymisées) en open data détaillent ainsi la fréquentation de chaque station de bus ou métro. "Si les validations billettiques fournissent un indicateur intéressant, elles ne permettent pas de reconstituer le trajet sauf dans les rares cas (comme le RER) où il y a une validation du titre de transport en sortie. Par ailleurs, elles excluent la fraude", explique Vincent Loucel, data scientist chez Kisio digital, la filiale data de l'opérateur de transport Keolis. D’où l'idée d'exploiter les traces GPS des téléphones mobiles des utilisateurs. Concrètement, l'équipe de data scientists a exploité les données de localisation de l'application de transports publics Twisto, dans le cadre d'une expérimentation pilote menée à Caen. Des données qui ont permis de redessiner dynamiquement, à l'échelle d'une journée ou de plusieurs semaines, le "serpent de charge" de chaque ligne de transport. "L'avantage de la donnée GPS est de nous renseigner sur les origines-destinations, mais si sur un même segment il y a un bus et un vélo en libre-service nous ne pouvons pas dire précisément quel mode de transport est utilisé", précise Kisio. Les données GPS doivent en outre être nettoyées car il y a beaucoup de "bruit" comme les points GPS aberrants ou les données manquantes du fait d'un tunnel. Pour les rendre pleinement exploitables et voir émerger des informations complémentaires comme le changement de mode de transport, elles doivent être croisées avec les horaires, le tracé des lignes et des points d'intérêt (gare, parking…). Enfin, elles supposent un important travail préalable d'anonymisation pour être en règle avec le RGPD. "À partir du moment où l'application est active, nous savons tout de la personne : là où elle habite et dans quelle entreprise elle travaille", explique l'expert. Il a donc fallu "flouter" une partie des données avant de les exploiter.
Modéliser les déplacements à l'échelle francilienne
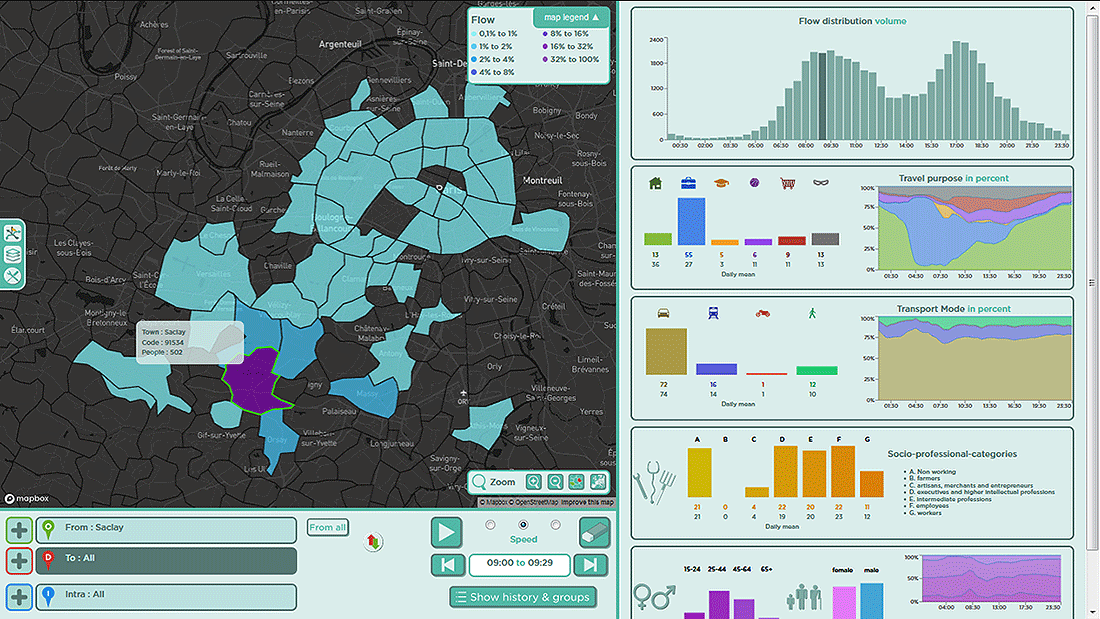
Un travail de retraitement loin d'être à la portée de tout le monde qui explique sans doute le fait que les données GPS des applications de mobilité soient aujourd'hui si peu utilisées par les transporteurs. Des limites qui ont conduit la start-up Entropy, issue d'un programme de recherche de l'institut Vedecom, à explorer une autre piste. "Nous estimons que 80% des usagers ont un comportement qui est identique d'un jour sur l'autre, d'une semaine à l'autre. Il est donc tout à fait possible de les modéliser" explique Guilhem Sanmarty, fondateur d'Entropy. Conçu à l'échelle de l'Ile-de-France, le projet a commencé par récupérer toutes les données disponibles à l'échelle du territoire : EMD, validations billettique, cartographie des infrastructures, routes et points d'intérêt, localisations des bus et des GPS voiture, données Insee (démographie, enquête ménage…) ainsi que celles de différentes applications mobiles comme celles d'Ile-de-France mobilités. Les data scientists ont ensuite appliqué des techniques d'intelligence artificielle du type "apprentissage profond" pour établir des liens statistiques entre les variables individuelles, les données urbaines et les formes de mobilité. Grâce à cette modélisation, la start-up a réussi à établir des cartes dynamiques représentant les volumes et motifs de déplacement par catégorie d'usager (professionnels, étudiants…), les parts modales, toutes les demi-heures de la journée pour un jour type de la semaine. Ce tableau de bord est aujourd'hui employé comme outil d'aide à la décision par plusieurs collectivités dont la ville de Rambouillet. "En jouant sur des horaires d'ouverture de bâtiments publics, nous avons par exemple pu décongestionner un axe routier majeur du département des Yvelines", relate Guilhem Sanmarty. Un outil qui s'affine avec les nouvelles données qu'on y injecte mais ne fait pas de l'acquisition de données un préalable à son utilisation. Au moins en Île-de-France.
Ce que disent les données de Blablacar
Boris Mericskay, maître de conférences en géographie à l'université Rennes 2, a exploité cinq mois de données de Blablacar ayant pour origine et destination Rennes (15.000 trajets). Contrairement à une idée reçue, BlaBlaCar serait moins positionné sur la longue que la moyenne distance. Les déplacements intra-bretons constituent en effet la majorité des trajets avec une distance parcourue comprise entre 160 à 180 km. Le trio des villes les plus visitées en covoiturage est, dans l'ordre, Nantes, Paris et Saint-Brieuc. Autre enseignement : l'important décalage de fréquentation entre les aires d'autopartage mises à disposition par les collectivités et les pratiques des usagers de Blablacar. À Rennes, le lieu-dit "La Poterie" arrive ainsi largement en tête car il concilie desserte en métro, parking et proximité de la rocade. Des données que le chercheur incite les collectivités locales à exploiter pour définir les emplacements des aires de covoiturage.